![NLP [P3] - Seq2Seq Model - Hạt nhân của Google Translate](/assets/img/2019-05-18-nlp-p3/seq2seq_3.png)
NLP [P3] - Seq2Seq Model - Hạt nhân của Google Translate
Kể từ khi các kiến trúc mạng RNN, LSTM ra đời, công việc dịch thuật đã bước một bước phát triển lớn. Khi nói tới translate thì không thể không nhắc tới ông lớn Google với sự đóng góp của Google Translate. Có thể nói Google Translate đang làm rất tốt công việc của mình trong mảng dịch máy. Hôm nay, mình xin giới thiệu một mô hình rất quan trọng trong dịch máy đó là Sequence-To-Sequence ( Seq2Seq ) hiện nay đang được Google sử dụng cùng với kĩ thuật Attention sẽ được mình nói kĩ hơn vào những bài viết sau. Trong bài viết có nhắc đến 2 kiến trúc mạng RNN và LSTM, nếu đây là lần đầu tiếp xúc với 2 kiến trúc này, bạn nên tham khảo 2 bài viết trước đó của mình.
Bài toán sinh chuỗi
Trong Xử lý ngôn ngữ tự nhiên, chúng ta thường gặp phải những bài toán cần sinh ra một chuỗi đầu ra từ một chuỗi đầu vào có sẵn ví dụ có thể kể đến như:
hệ thống dịch tự động: Từ một chuỗi tiếng Anh, trả lại chuỗi tiếng Việt có ý nghĩa tương ứng.hệ thống chatbot: Tự động sinh câu trả lời từ câu thoại của người dùng.
Trong việc xử lí những bài toán trên, seq2seq thể hiện tính hiệu quả vượt trội của mình.
Cấu trúc mạng
Thành phần chính của seq2seq bao gồm phần Encoder và Decoder. Encoder sẽ đảm nhiệm công việc trích xuất thông tin từ chuỗi đầu vào và cung cấp nó cho Decoder. Decoder sẽ thực hiện quá trình sinh chuỗi mới từ thông tin mà Encoder cung cấp.

Encoder và Decoder có thể được xây dựng từ những kiến trúc mạng như RNN, LSTM, GRU. Trong phạm vi bài viết này, mình sẽ nói về LSTM.
Encoder
Trong những bài viết trước, mình có nhắc tới vấn đề lưu trữ thông tin của câu, và việc LSTM có thể xử lí được vấn đề phụ thuộc xa mà RNN mắc phải. Nói các khác, LSTM đã khắc phục được nhược điểm là lưu trữ thông tin của những câu có độ dài lớn. Bằng việc xử lí thông tin và lưu trữ dữ liệu vào các cell state, LSTM có thể đem được thông tin của các từ trong câu đi một khoảng cách xa.
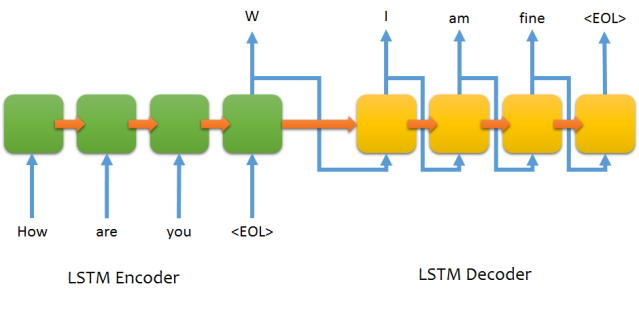
Công việc chính của lớp Encoder là mã hoá các từ đầu vào bằng một chuỗi các lớp RNN, LSTM nhằm đưa ra vector state cuối cùng, vector này sẽ là thông tin đầu vào cho lớp Decoder. Tại sao lại sử dụng vector state cuối cùng mà không phải toàn bộ?
Lấy ví dụ đơn giản trong mạng RNN:
X = “How are you?”
x1 = How
x2 = are
x3 = you
Công việc tính toán các state sẽ được thực hiện như sau:
S1 = ƒ( S0 , x1 )
S2 = ƒ( S1 , x2 ) =ƒ (ƒ ( S0 , x1 ) , x2 )
S3 = ƒ( S2 , x3 ) =ƒ( ƒ( ƒ( S0 , x1 ) , x2 ) , x3 )
Có thể thấy S3 đã mang được thông tin của x1, x2, x3 theo, dễ thấy S3 có thể đại diện cho toàn bộ thông tin của câu How are you.
Decoder
Khi sử dụng LSTM, đầu ra của Encoder sẽ là 2 vector trạng thái C (cell state) và h (hidden state). 2 vector này sẽ được sử dụng làm init_state cho lớp LSTM đầu tiên của Decoder. Decoder sẽ bắt tay vào tính toán và sinh chuỗi mới từ 2 vector trạng thái này cho tới khi gặp ký tự
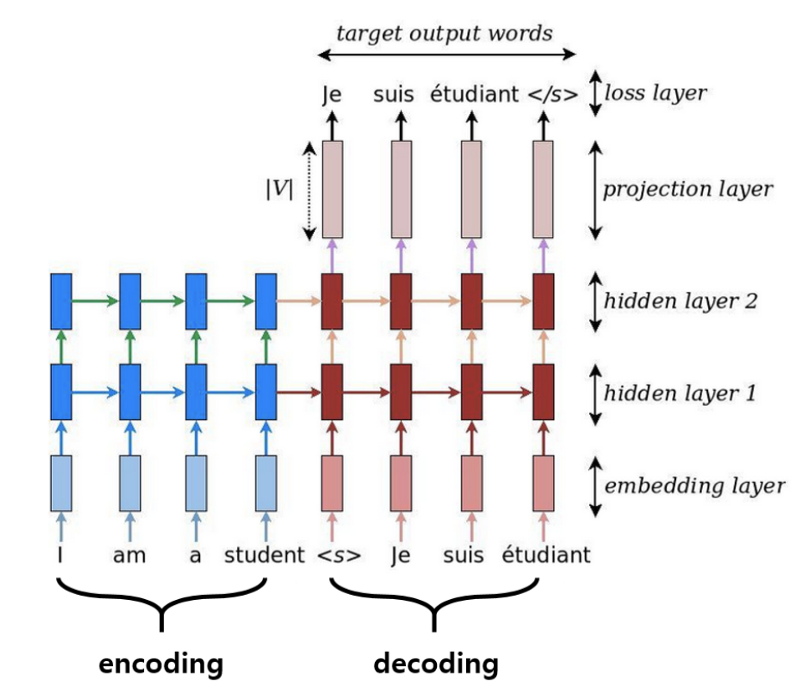
Vừa rồi mà sơ lược về mô hình Sequence-To-Sequence, nếu có thắc mắc hoặc góp ý gì vui lòng để lại comment cuối bài viết.
Bài viết tham khảo và sử dụng hình ảnh từ: