![NLP [P5] - Tìm hiểu về Attention Mechanism](/assets/img/2019-07-05-ky-thuat-attention/attention.jpg)
NLP [P5] - Tìm hiểu về Attention Mechanism
Trong bài viết trước NLP [P3] - Seq2Seq Model - Hạt nhân của Google Translate mình có đề cập tới kỹ thuật Attention hiện nay đang được sử dụng bởi Google Translate cùng với cấu trúc Encoder-Decoder. Đây là một kĩ thuật đã thay đổi khá nhiều hiệu quả của mảng Dịch Máy, ngoài ra, kỹ thuật này cũng được sử dụng trong một số những mảng khác như Computer Vision. Trong bài viết này, mình xin giới thiệu với bạn đọc kỹ thuật Attention được sử dụng với mô hình Seq2Seq trong bài toán Dịch Máy. Các bạn có thể tham khảo kĩ hơn trong bài báo Neural Machine Translation by Jointly Learning to Align and Translate
Get the ball rolling
Tưởng tượng bạn đang đi trên phố, có vô số người lướt qua mặt bạn, vậy để làm thế nào để bạn có thể nhận biết được đó là người quen hay không? Dĩ nhiên rồi, nhìn mặt là biết. Vậy hành động của bạn chỉ có nhìn mặt chứ không phải nhìn trang phục, chân, tay… hay chính xác là bạn chỉ chú ý (attention) vào khuôn mặt của người đó. Trong dịch máy cũng vậy, ví dụ bạn cần dịch câu sau sang tiếng Anh:
[Con\ cá\ đang\ bơi\ trong\ chậu\ nước]
Để quyết định từ cá ở đây là fish hay bet (cá cược) thì ta cần thêm những thông tin khác ví dụ như bơi, chậu nước. Vậy có nghĩa để xác định xem từ tiếp theo ra cần attention vào những từ khác trong câu nữa. Đây cũng chính là ý nghĩa của kỹ thuật Attention. Quyết định dựa trên một hoặc nhiều thành phần thông tin đầu vào, chứ không phải tất cả.
Encoder-Decoder Model
Quay trở lại với mô hình Encoder-Decoder, với mỗi input $x_t$ đầu vào, mạng RNN sẽ xử lí đưa ra một vector $h_t$ mang thông tin về từ đó và tính tuần tự của nó với những từ phía trước. Kết quả của quá trình xử lí cả câu sẽ là một vector trạng thái c cuối cùng.
[h_t=f\left( x_t, h_{t-1} \right)]
[c=q\left({h_1,…,h_{T_x}}\right)]
$h_t$ ở đây là trạng thái ẩn ở mốc thời gian $t$. $f$ và $q$ là những hàm phi tuyến. Kết quả của quá trình Encoder chính là $q\left({h_1,…,h_T}\right)$ = $h_T$ chính là vector trạng thái ẩn cuối cùng.
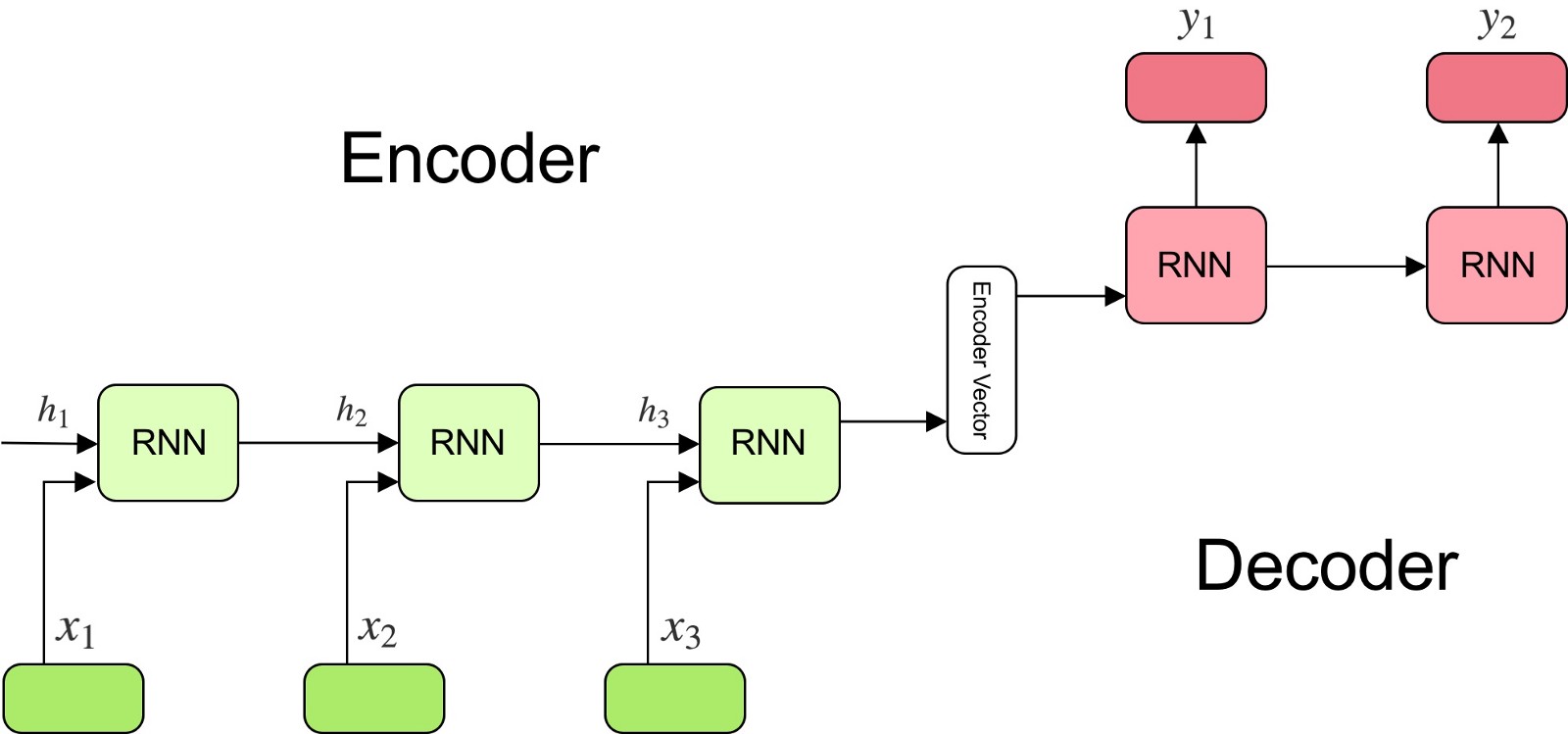
Sau khi đã có được vector Encode, quá trình Decoder sẽ thực hiện dự đoán từ $y_{t’}$ dựa trên vector c và tất cả những từ được dự đoán trước đó ${ y_1, …, y_{t-1}, c}$. Xác suất của cả câu sau quá trình decode sẽ là:
| [p\left(y\right) = \prod_{t=1}^T p\left(y_t | { y_1, …, y_{t-1}}, c\right)] |
Với xác suất của mỗi từ:
| [p\left(y_t | {y_1, …, y_{t-1}}, c\right) = g\left(y_{t-1}, s_t, c\right)] |
Ở đây, $g$ là một hàm phi tuyến cho kết quả đầu ra là xác suất của $y_t$, $s_t$ là trạng thái ẩn của mạng RNN. Vector c được sử dụng với ý nghĩa rằng chúng ta sử dụng tất cả dữ liệu trước đó để dự đoán từ tiếp theo.
Kỹ thuật Attention
Như đã đề cập ở trên, chúng ta cần biết được cần tập trung vào phần nào của dữ liệu đầu vào, để làm được việc này thì ta cần một đại lượng đặc trưng cho sự quan trọng của dữ liệu. Chính xác hơn thì ta cần biết cần ghi nhớ phần nào và bỏ quên phần nào. Trọng số của phần đó càng lớn có nghĩa rằng thông tin cần tập trung khai thác ở đó và ngược lại. Cùng đánh giá công thức tính toán xác suất của mỗi đầu ra tại bước Decoder của kỹ thuật Attention:
| [p\left(y_t | {y_1, …, y_{t-1}}, c\right) = g\left(y_{t-1}, s_t, c_i\right)] |
Thoạt nhìn thì có vẻ công thức này không khác là mấy so với phần Decoder thông thường. Nhưng ở đây vector c đã được thay thế bởi $c_i$ khác nhau với mỗi $y_i$. $s_i$ ở đây chính là trạng thái ẩn của mạng RNN tại mốc thời gian $i$, được tính như sau:
[s_i=f\left(s_{i-1}, y_{i-1}, c_i\right)]
Thay vì sử dụng một vector c cố định, giờ đây tại mỗi thời điểm, vector c sẽ được tính toán lại dựa vào tập $\left(h_1, …, h{T_x}\right)$. Mỗi $h_i$ sẽ đại diện cho toàn bộ phần thông tin trước thời điểm $i$ và đặc biệt tập trung vào thông tin của từ thứ $i$. Vector c sẽ được tính toán như sau:
[c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j]
$\alpha_{ij}$ chính là trọng số của từng từ, được tính bằng hàm Softmax:
[\alpha_{ij}=\frac{\exp\left(e_{ij}\right)}{\sum_{k=1}^{T_x}\exp\left(e_{ik}\right)}]
[e_{ij}=v_a^T\tanh\left(W_a s_{i-1} + U_a h_j\right)]
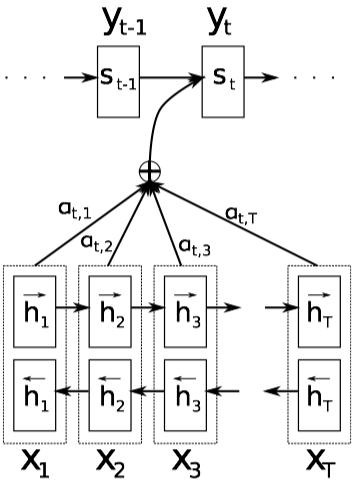
$e_{ij}$ được tính bằng trạng thái ẩn của từ trước đó trong phần Decoder và vector $h_j$ trong phần Encoder với $v_a^T, W_a, U_a$ là các ma trận weights. Như vậy, chúng ta đã giải quyết được việc tại mỗi bước dự đoán $y_i$, ta chỉ sử dụng một số thông tin nhất định, được tính toán bằng cách đánh trọng số cho mỗi input đầu vào. Về chi tiết các công thức tính toán, tác giả xin phép không liệt kê chi tiết trong bài viết này, bạn đọc vui lòng tham khảo trong bài báo.
Bài viết được tham khảo và sử dụng hình ảnh từ: