
Attention Mechanism in OCR - Tìm hiểu về kỹ thuật Attention trong Nhận dạng kí tự, chữ
Từ bài viết trước mình có đề cập tới vấn đề sử dụng kĩ thuật Attention trong Computer Vision. Khi gặp mặt một người, để quyết định xem đó có phải người quen của mình không, ta thường chú ý vào khuôn mặt của người đó. Xét trên khía cạnh hình ảnh, thì lúc đó ta chỉ tập trung vào lượng thông tin ở vùng ảnh ở khuôn mặt. Trong bài viết này, mình xin giới thiệu tới bạn đọc một cấu trúc RNN + CNN + Attention Mechanism giúp giải quyết bài toán OCR (Optical Character Recognition). Cụ thể, cấu trúc này đã đạt được 84.2% trên tập dữ liệu biển báo ở Pháp - FSNS (French Street Name Signs), mở ra một hướng đi mới cho bài toán nhận dạng chữ. Thông tin chi tiết bạn đọc có thể tham khảo trong bài báo Attention-based Extraction of Structured Information from Street View Imagery
- Kiến trúc tổng quát
- CNN feature extraction
- RNN Word prediction
- Tính toán Attention mask
- Thông tin vị trí
- Xử lý vấn đề nhiều view của data FSNS
Kiến trúc tổng quát
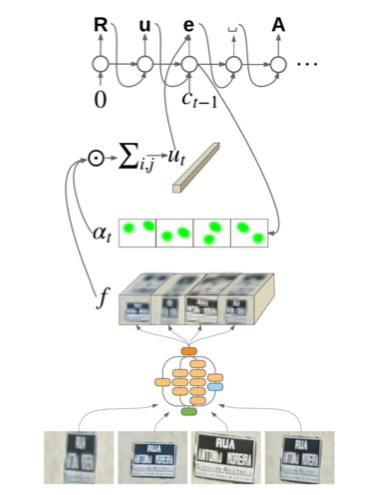
Nhìn chung, Attention-OCR sẽ sử dụng những tầng CNN để trích xuất các đặc trưng của bức ảnh. Sau đó sẽ dùng một Attention-mask để biến đổi feature maps thành một vector đầu vào của mạng RNN hoặc LSTM sau khi đã tập trung sự chú ý vào một vùng ảnh nào đó.
CNN feature extraction
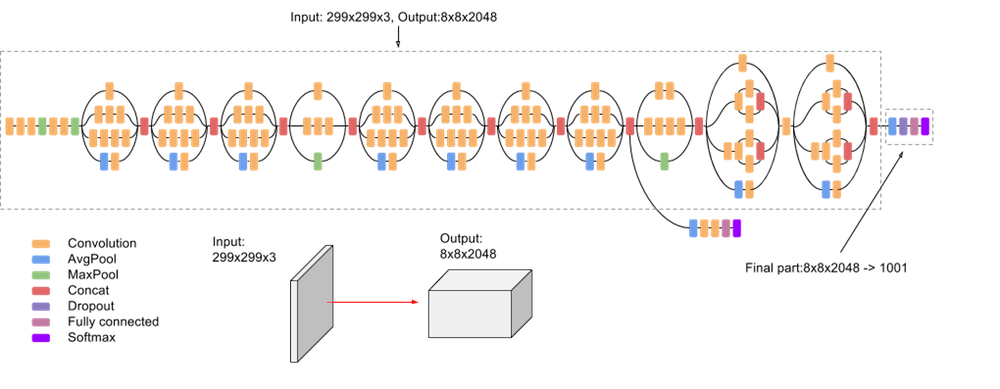
Cấu trúc mạng CNN được đề xuất sử dụng sau một quá trình thử nghiệm để chọn ra cấu trúc của hiệu năng tốt nhất chính là InceptionV3. Bài báo cũng chỉ ra rằng, tầng CNN sâu không phải là tốt, tầng CNN được đề xuất trong cấu trúc InceptionV3 là tầng Mixed_5d.
Để thuận lợi cho việc biểu diễn công thức tính toán, tác giả đề xuất $f={f_{i,j,c}}$ để biểu thị vị trí $i, j$ trong mạng CNN với $c$ là số channels.

RNN Word prediction
Công việc của tầng RNN là chuyển đổi feature maps từ tầng CNN thành một vector đầu vào giống như trong Language Model. Với $s_t$ là trạng thái ẩn của mạng LSTM tại thời điểm t, vector attention được tính toán từ feature maps và một mặt nạ attention như sau:
[u_{t,c}=\sum_{i,j}\alpha_{t,i,j}f_{i,j,c}]
Việc nhân tích vô hướng mặt nạ attention cùng kích vỡ với feature maps với độ sâu là $c$ sẽ cho ra một vector $u={u_0, …, u_{c-1}}$. Tổng hợp lại vector đầu vào của mạng LSTM tại thời điểm t:
[\hat{x}t = W_c c{t-1}^{OneHot} + W_{u_1}u_{t-1}]
$W_c$, $W_{u_1}$ là các ma trận Weights, $c_{t-1}$ ở đây là vector one-hot của từ phía trước đó (là groundtruth trong quá trình training hoặc là dự đoán của từ trước đó trong quá trình test)
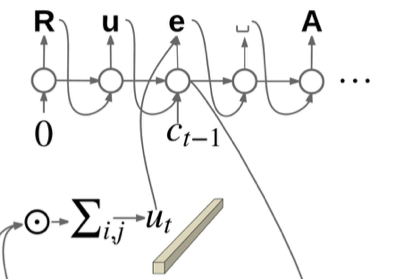
Output và Trạng thái ẩn của mạng LSTM được tính toán từ input và trạng thái ẩn trước đó.
[\left(o_t, s_t\right) = RNNstep\left(\hat{x},s_{t-1}\right)]
Kết quả cuối cùng $c_t$ được tính bằng cách chọn index có giá trị lớn nhất thông qua hàm Softmax:
[\hat{o}=\operatorname{softmax}\left(W_o o_t + W_{u_2} u_t\right)]
Thông tin được tổng hợp từ $o_t$ và vector attention $u_t$.
[c_t=\underset{c}{\operatorname{argmax}}\hat{o}_t\left(c\right)]
Tính toán Attention mask
Nhắc lại công thức tính chỉ số attention ở bài NLP [P5] - Tìm hiểu về Attention Mechanism:
[e_{ij}=v_a^T\tanh\left(W_a s_{i-1} + U_a h_j\right)]
Ở đây trọng số attention sẽ được tính toán từ thông tin trạng thái ẩn và vector đầu ra của mạng RNN $h_j$. Tham số này được thay thế bởi thông tin của feature map $f_{i,j,:}$
[a_{t,i,j} = V_a^T\operatorname{tanh}\left(W_s s_t + W_f f_{i,j,:}\right)]
[\alpha_t = \operatorname{softmax}_{i,j}\left(a_t\right)]
với $V_a$ là một vector. $a_{t,i,j}$ biểu diễn cho sự chú ý vào vị trí $i, j$ trên feature map tại thời điểm $t$. Trọng số này được tổng hợp từ thông tin từ bức ảnh thông qua $W_f f$ và thông tin về thời gian $W_s s_t$ để xác định cần chú ý vào đâu.
Thông tin vị trí
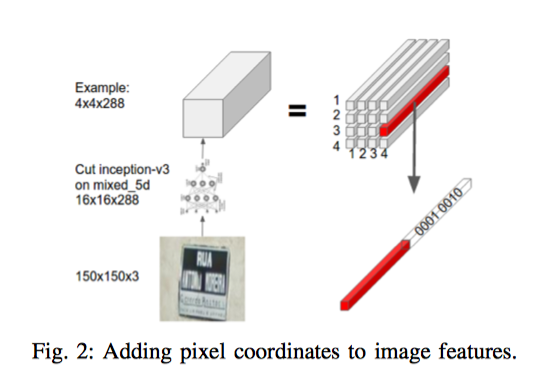
Tuy nhiên, việc sử dụng công thức tính trọng số attention trên có thể làm mất tính tuần tự của các pixel. Vì vậy, bài báo đề xuất bổ sung thêm thông tin về vị trí của các pixels bằng cách nối thêm một vector one-hot của toạ độ $\left(i,j\right) vào feature maps. Công thức sẽ trở thành:
[a_{t,i,j} = V_a^T\operatorname{tanh}\left(W_s s_t + W_f f_{i,j,:} + W_{f_2}e_i + W_{f_3}e_j\right)]
với $e_i$ và $e_j$ lần lượt và các vector one-hot của toạ độ $i, j$.
Xử lý vấn đề nhiều view của data FSNS
Tập dữ liệu của FSNS gồm 4 góc nhìn khác nhau, mỗi góc nhìn là một ảnh với kích cỡ 150x150.


Bài báo đề xuất xử lý độc lập từng ảnh một qua các tầng CNN như nhau, sau có kết nối chúng lại theo chiều ngang để được feature map cuối cùng. Ví dụ mỗi ảnh sau tầng CNN từ kích cỡ 150x150 sẽ còn 16x16x320 tương ứng với $f_{i,j,c}$. Sau đó 4 ảnh sẽ được kết nối lại thành 64x16x320 như chúng ta thấy trong kiến trúc tổng quát.
Thông tin về quá trình training và visualize bạn đọc vui lòng tham khảo trong bài báo.

Bài viết được tham khảo và sử dụng hình ảnh từ: