
Tìm hiểu về CTPN - Connectionist Text Proposal Network
Bài toán Object Detection từ lâu đã được phát triển và đạt được nhiều thành tự bằng các cấu trúc đặc biệt như Faster RCNN, SSD - Single Shot Detector, YOLO, … Tuy nhiên, vấn đề Text Detection lại có chút đặc biệt hơn so với các dạng Object khác bở i bản thân Text không phải là một Text Object mà là một chuỗi các Text nối tiếp nhau. Vậy làm sao để có thể giải quyết bài toán Text Detection? Trong bài viết này, mình xin giới thiệu tới bạn đọc cấu trúc Connectionist Text Proposal Network - CTPN dùng trong bài toán Text Detection.
Hướng tiếp cận
Có thể bạn đọc đã quá quen thuộc với những thủ tục Captcha của Google. Như ví dụ dưới đây:


Công việc của chúng ta là lựa chọn những khối vuông chứa thông biển báo giao thông.
Việc sử dụng captcha này dùng để xác nhận xem người dùng có phải là người máy hay không, đồng thời hỗ trợ cho AI của Google tự học bài toán Object Detection. Như ví dụ trên, ta lựa chọn 5 ô vuông kia bởi ta nghĩ rằng 5 ô vuông đó có chứa thông tin của biển báo. Vậy giả sử yêu cầu trên trở thành hãy chọn những vùng có chứa text thì sao?
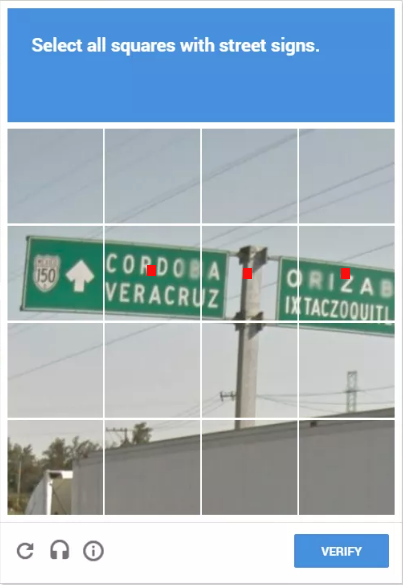

Lúc này, vấn đề bắt đầu xuất hiện. Ta sẽ chọn 3 ô vuông như trên, và như ta để ý, thì ô vuông ở giữa chỉ chứa một vài vùng của Text ở 2 phía của biển báo. Để có thể lựa chọn các vùng chính xác hơn, ta có thể nghĩ tới phương pháp chia nhỏ những ô vuông trên hơn nữa.
Vậy, chúng ta có thể chia nhỏ bài toán Text Detection thành chọn những vùng có chứa text trên bức ảnh, đây chính là ý tưởng chính của cấu trúc Connectionist Text Proposal Network.

Kiến trúc của CTPN
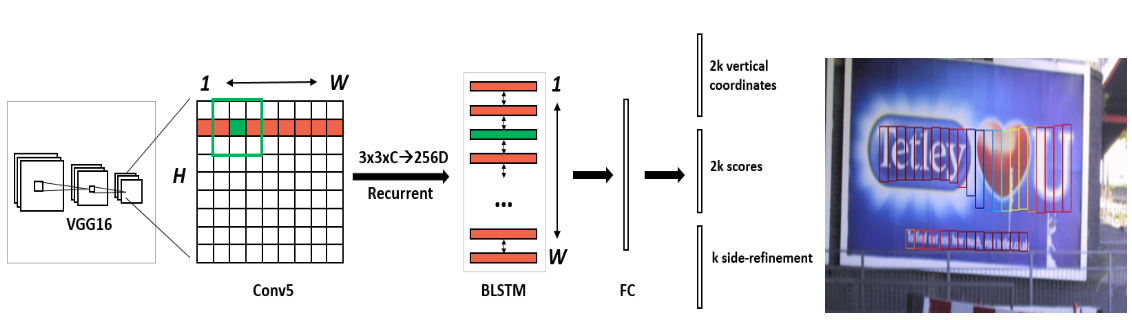
CTPN sử dụng cấu trúc VGG16 để extract các feature sau đó dùng tầng Conv5d giống như việc phân ô nhỏ ở ví dụ trên. CTPN sẽ dùng một cửa số 3x3 (sliding-window) qua mỗi vị trí trên feature map. Kết quả của chuỗi cửa sổ trên một hàng của feature map sẽ được kết nối với một mạng Bi-directional LSTM. Sau đó lớp RNN sẽ được kết nối với một lớp fully-connected layer. Kêt quả cuối cùng sẽ mang thông tin về dự đoán text/non-text, tọa độ dọc và phần bù của $k$ anchor. Thông tin về các anchor sẽ được mình làm rõ ở phần sau.
Connectionist Text Proposal Network
CTPN sẽ thực hiện 3 công việc chính:
- Detecting Text in Fine-scale Proposals
- Recurrent Connectionist Text Proposals
- Side-refinement
Detecting Text in Fine-scale Proposals
Việc phát hiện kí tự trong môi trường tự nhiên rất phức tạp bởi ta có thể nhầm lẫn giữa background và text ở những vị trí mà sự thể hiện của text yếu ớt ví dụ như ở những nét nhỏ, khoảng trống giữa các chữ cái. Vì vậy nếu với cách tiếp cận Object Detection thông thường, sẽ rất dễ xảy ra trường hợp bounding box không bao quát đủ không gian của Text đặc biệt trong trường hợp Text có kích thước nhỏ. CTPN định nghĩa một dòng text là một chuỗi các fine-scale text proposals với mỗi proposal sẽ chứa một phần nhỏ của dòng text. CTPN mong muốn rằng mỗi proposal sẽ chứa một hoặc nhiều nét, một hoặc nhiều kí tự, một phần kí tự của dòng chữ.
Để làm được điều này, CTPN sẽ mapping các vị trí trên feature map với một proposal trên input image. Thông thường mỗi proposal sẽ có width là 16 pixels, chiều cao sẽ được dự đoán bằng mô hình. Quay trở lại với khái niệm anchor, với mỗi proposal, CTPN sẽ khởi tạo $k$ anchors với những chiều cao khác nhau. CTPN sử dụng 10 anchor với chiều cao sẽ nằm trong khoảng từ 11 đến 273 (chia cho 0.7 sau mỗi anchor). Như vậy với mỗi anchor sẽ chứa thông tin về vị trí và kích thước.
Công việc lúc này đó là dự đoán các thông số vị trí và kích thước tương đối so với từng anchor ứng với mỗi proposal. Vị trí tương đối của dự đoán và groundtruth được tính như sau:
Prediction:
[v_c=\left(c_y-c_y^a\right)/h^a]
[v_h=\log\left(h/h^a\right)]
Proposal Groundtruth:
[v_c^=\left(c_y^-c_y^a\right)/h^a]
[v_h^=\log\left(h^/h^a\right)]
Với $v={v_c,v_h}$ và (v^={v_c^,v_h^*}) là tọa độ của kết quả dự đoán và groundtruth
$c_y^a$ và $h^a$ là trung tâm và chiều cao của anchor, tham số này có thể được tính toán trước từ ảnh đầu vào. Như vậy, mỗi dự đoán sẽ ứng với một proposal với kích thước là hx16. Những công thức này chỉ được tính toán trên những anchor mà có chỉ số text/non-text > 0.7
Recurrent Connectionist Text Proposals
Việc chia nhỏ cả dòng text thành những fine-scale text proposals và dự đoán nó có phải là text hay không có thể gặp nhầm lẫn ở những trường hợp khoảng cách giữa những kí tự xa hoặc nhầm lẫn những đối tượng có cấu trúc gần giống với text. Vì một dòng text có tính tuần tự liên quan với nhau giữa các kí tự trong một từ, một từ trong câu, vì vậy, CTPN đã sử dụng cấu trúc mạng RNN để nhận mỗi vùng convolutional feature window như một đầu vào của từ. Để khắc phục được sự phụ thuộc xa thì CTPN cũng dùng cấu trúc mạng LSTM. Các hidden layer của mạng LSTM sẽ được cập nhật:
[H_t=\phi\left(H_{t-1}, X_t\right)]
với $X_t\in R^{3\times 3 \times C}$ là vùng convolutional feature window thứ $t$ của cửa sổ $\left( 3\times 3\right)$. t = 1, 2, … , W với W là chiều rộng của tầng conv5. $H_t$ là hidden state sẽ được tính toán từ $X_t$ và hidden state $H_{t-1}$ trước đó bằng hàm phi tuyến $\phi$ được định nghĩa trong cấu trúc mạng RNN tương ứng sử dụng.
Side-refinement
Sau khi đã có tập hợp những text proposal với điểm số text/non-text > 0.7, bounding box của một text sẽ được xây dựng bằng cách kết nối các text proposal còn lại bằng trình tự sau:
- $B_j$ được cho là một cặp với $B_i$ theo những tiêu chí sau:
- $B_j$ gần $B_i$ nhất xét theo chiều ngang
- Khoảng cách này phải nhỏ hơn 50 pixels
- Chỉ số ovelap theo chiều dọc > 0.7.
- $B_j$ sẽ được ghép với $B_i$ nếu $B_j$ là một cặp với $B_i$ và ngược lại
Vì dòng text sẽ được chia nhỏ thành một chuỗi proposal 16-pixel nên sẽ xảy ra trường hợp những proposal ở 2 phía của dòng text sẽ bị bỏ qua vì chỉ chứa một phần nhỏ của text. Vì vậy, CTPN sẽ khắc phục bằng cách dự đoán thêm một phần bù của proposal ở 2 phía.
[o=\left(x_{side} - c_x^a \right)w^a]
[o^=\left(x^_{side} - c_x^a\right)/w^a]
$x_{side}$ là vị trí của tọa độ x - theo chiều ngang gần nhất tới anchor hiện tại ở cả 2 phía. $x_{side}^*$ là phần bù groundtruth được tính toán trước từ groundtruth box và vị trí của anchor. $c_x^a$ là tâm điểm của anchor theo x-axis, $w^a$ là chiều rộng của anchor (được fixed $w^a$=16). Việc sử dụng phần bù có thể khắc phục được việc bounding box không bao được hết dòng text đặc biệt trong trường hợp kích thước nhỏ.

Cách tính hàm Loss và quá trình Training bạn đọc vui lòng tham khảo thêm trong bài báo.
Bài viết được tham khảo và sử dụng hình ảnh từ: